Mysterys lösen: Einfache Buchstabenersetzung (monoalphabetische Substitution) knacken
 Machen wir mit unserem Beispiel aus der Geheimschrift weiter Eine Häufigkeitsanalyse Ein Häufigkeitsgebirge für unseren Geheimtext Detektivarbeit: Kombinieren, Suchen, Ersetzen Wortanalyse dank Satz- und Leerzeichen Bigramme und deren Nutzen für unsere Analyse Nach Geocaching-Begriffen suchen Weitere Wörter kombinieren / vervollständigen Online-Solver für Eilige oder Faule
Machen wir mit unserem Beispiel aus der Geheimschrift weiter Eine Häufigkeitsanalyse Ein Häufigkeitsgebirge für unseren Geheimtext Detektivarbeit: Kombinieren, Suchen, Ersetzen Wortanalyse dank Satz- und Leerzeichen Bigramme und deren Nutzen für unsere Analyse Nach Geocaching-Begriffen suchen Weitere Wörter kombinieren / vervollständigen Online-Solver für Eilige oder Faule Unser Text besteht aus einem sinnlosen Text, die Buchstaben A bis Z sind darin durcheinander gewürfelt. Und wir haben festgestellt (oder nehmen dies mit großer Wahrscheinlichkeit an), dass wir eine einfache Buchstabenersetzung, eine sogenannte monoalphabetische Substitution vor uns haben. Dafür wird eigentlich niemals ein Schlüssel mitgeliefert, denn der Schlüssel ist die Buchstabenvertauschung an sich, also welcher Buchstabe durch welchen anderen (wobei er durchaus auch gleich bleiben kann) ersetzt wird. Trotzdem ist es im Grunde genommen eine Chiffre und kein Code. Aber das ist jetzt nebensächlich.
Haben wir zum Beispiel einen Geheimtext in die lateinischen Buchstaben A bis Z überführt (trankribiert), dann ist daraus eine folgende von durcheinandergewürfelten Buchstaben geworden. Arbeiten wir doch am Beispiel aus dem Kapitel Mysterys lösen: Das Rätsel besteht aus fremden Schriftzeichen weiter. Dort kann auch nochmal der untranskribierte Geheimtext angeschaut werden.
Machen wir mit unserem Beispiel aus der Geheimschrift weiter
Wir hatten dort mit dem Transkript "ABCDEFGCHIEJ! KC JLIM KLI NLDMIDB ADBODIM. KC PQHKDIM KQD KOID QH KDN GCNRDB DQHDI CSADPLBBDHDH TLCSDI TDQ KDH FOONKQHLMDH HONK RGDQCHKPCDHPRQA ANLK HCBB UCHFM IQDTDH HCBB HCBB SQHCMDH CHK OIM LEJM ANLK HDCHCHKRGLHRQA UCHFM VQDN IQDTDH DQHI SQHCMDH. VQDB IULII!" geendet.Wir hatten die Buchstaben ja der Reihe nach aus dem Alphabet für unser Transkript vergeben. Und sind bis zum "V" gekommen. Das sind 22 vergebene Buchstaben und spricht für den Gebrauch eines kompletten Alphabets. Jeder Buchstabe steht dabei für einen anderen (oder zufälligerweise auch den gleichen).
Für den nächsten Schritt wird wieder der Kontext wichtig. Nehmen wir an, der betreffende Geocache ist in der Nähe von Bielefeld im Teutoburger Wald gelistet und die Listingkoordinaten sind N52° 01.000 und E008 30.000. Hinweise in Form von Titel oder Hint gibt es nicht. Die Terrainwertung liegt bei 2, die Dosengröße ist regular.
Eine Häufigkeitsanalyse
Die ursprüngliche Sprache für den Geheimtext wird demnach Deutsch gewesen sein. Warum das wichtig ist? Weil wir uns jetzt als Nächstes die Häufigkeitsverteilung der deutschen Buchstaben besorgen. Die kann man übersichtlich in einem Häufigkeitsgebirge darstellen: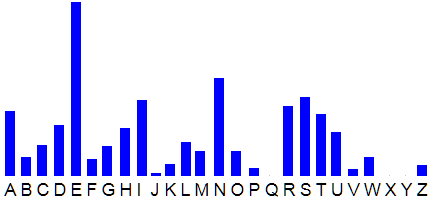
Wir sehen, dass das "E" der mit Abstand häufigste Buchstabe (ca. 17,4%) im Deutschen ist. Danach folgt das N (ca. 9.8%) mit kleinem Abstand zu S, R, T, I und A (alle nahe beieinander zwischen 6.5% und 7.9%). Das ist auch der Grund dafür, dass beim Glücksrad so gerne der "Ernstl" genommen wurde, weil man ihn sich halt gut merken kann und diese Buchstabenkombination die meistvorkommenden Buchstaben abdeckt, man so die größte Chance hat, möglichst viele Buchstaben erraten zu haben. Aber das nur nebenbei. Zurück zum Thema.
Das heißt, dass der am häufigste Buchstabe in unserem Chiffrat (dem Transkript) mit großer Wahrscheinlichkeit das E (weil am häufigsten vorkommend) ist und der zweithäufigste Buchstabe mit weniger großer Wahrscheinlichkeit das N. Dann folgen S, R, T, I und A. Bei denen können wir uns aber nicht so sicher sein, was was ist, denn deren Häufigkeiten liegen doch recht nah beeinander und die exakten erreicht man höchstens bei sehr sehr langen Texten. Bei kurzen Texten, so wie wir einen vorliegen haben, gibt es natürlich Schwankungen. Und am Ende der Skala kommen die selteneren Buchstaben. Das ist auch nicht unnütz, denn seltene Buchstaben im Chiffrate sind wahrscheinlich seltene Buchstaben im Deutschen.
Ein Häufigkeitsgebirge für unseren Geheimtext
Am Ende der Seite Häufigkeitsverteilung auf Kryptografie.de kann man sich für jeden Text ein eigenes Häufigkeitsgebirge erstellen lassen, was wir für "ABCDEFGCHIEJ! KC JLIM KLI NLDMIDB ADBODIM. KC PQHKDIM KQD KOID QH KDN GCNRDB DQHDI CSADPLBBDHDH TLCSDI TDQ KDH FOONKQHLMDH HONK RGDQCHKPCDHPRQA ANLK HCBB UCHFM IQDTDH HCBB HCBB SQHCMDH CHK OIM LEJM ANLK HDCHCHKRGLHRQA UCHFM VQDN IQDTDH DQHI SQHCMDH. VQDB IULII!" mal machen wollen. Alternativ kann man natürlich den Mystery Master benutzen. Ich habe da schon mal einen Link vorbereitet. Einfach hier draufklicken für das fertige Gebirge.Das Ergebnis ist:

Detektivarbeit: Kombinieren, Suchen, Ersetzen
Demnach könnte das "D" (am häufigsten) für das "e" stehen und das "H" (am zweithäufigsten) für das "n". Ich schreibe hier und im Folgenden die Geheimtextbuchstaben GROSS und die Klartextbuchstaben klein. Denn so wird unsere Vorgehensweise: Wir ersetzen nach und nach Großbuchstaben durch Kleinbuchstaben, um so den Klartext offen zu legen. Hier empfiehlt sich ein guter Texteditor, der zwischen Groß- und Kleinschreibung beim Ersetzen unterscheiden kann und der einen großen Rückgängigmachen-Speicher hat (alternativ geht natürlich auch immer wieder Text kopieren). Ich glaube, auch Word wäre dafür geeignet. Legen wir einfach mal los. Wenn wir D->e und H->n ersetzen, erhalten wir:ABCeEFGCnIEJ! KC JLIM KLI NLeMIeB AeBOeIM. KC PQnKeIM KQe KOIe Qn KeN GCNReB eQneI CSAePLBBenen TLCSeI TeQ Ken FOONKQnLMen nONK RGeQCnKPCenPRQA ANLK nCBB UCnFM IQeTen nCBB nCBB SQnCMen CnK OIM LEJM ANLK neCnCnKRGLnRQA UCnFM VQeN IQeTen eQnI SQnCMen. VQeB IULII!
Die kleinen Buchstaben sind jetzt die angenommenerweise Richtigen. Die großen Buchstaben sind noch unersetzt und falsch. So können wir immer erkennen, welche Buchstaben noch zu ersetzen sind (nämlich die großen) und welche wir schon ermittelt und vergeben haben (die kleinen). Und wir wissen damit auch, dass wir einen Großbuchstaben nie durch einen Buchstaben ersetzen dürfen, der da schon als Kleinbuchstabe steht, denn der ist ja schon vergeben. Am Anfang ist es aber vielleicht doch einfacher zwei Buchstabenreihen von A-Z zu führen, bei denen man durchstreicht, was man bereits ersetzt bzw. vergeben hat.Wortanalyse dank Satz- und Leerzeichen
Noch lässt sich nicht viel in unserem Text lesen. Aber der Owner war ja so freundlich die Leer- und Satzzeichen im Geheimtext drin zu lassen. Das macht uns die Sache einfacher, denn daraus können wir die ursprünglichen Wortlängen ableiten. Stürzen wir uns als erstes auf die kurzen Wörter. "KC" hat nur 2 Buchstaben und kommt gleich zweimal vor. und "K" steht im Geheimtext häufig am Anfang von Wörtern. Auf der Häufigkeitsverteilungs-Seite sind unter Anderem auch die zweibuchstabige Wörter im Deutschen aufgelistet.Da wir "e" und "n" schon vergeben haben, bleibt, vorausgesetzt unsere bisherigen Annahme waren richtig, noch
mit 'a': ab, am, an, da, ja
mit 'e': eh, er, es, je
mit 'i': im, in
mit 'o': ob, so, wo
mit 'u': du, um, zu, nu
Uns war ja auch aufgefallen, das "K" ziemlich häufig am Wortanfang vorkommt. Auch dazu weiß die Häufigkeitsverteilungs-Seite etwas:Die häufigsten Anfangsbuchstaben im Deutschen:

Schauen wir also nach Wörter mit zwei Buchstaben, die mit "d" oder "s" anfangen, das wären doch gute Kandidaten. Das wären dann "du" und "so". Hmm, beides möglich. Behalten wir das im Hinterkopf und suchen wir erstmal woanders. Mir fällt noch "Qn" auf. Wenn das "n" stimmt, spräche das für "in" oder "an". "i" und "a" kommen etwa gleich häufig im Deutschen vor. Da können wir uns noch nicht wahrscheinlich genug festlegen.
Bigramme und deren Nutzen für unsere Analyse
Aber mir fällt ein, dass im Deutschen die Buchstabenkombination "ie" ziemlich häufig ist. Auch dazu gibt es etwas auf der der Häufigkeitsverteilungs-Seite und zwar unter Bigramme. "Bigramm" heißt nichts anderes als Kombination aus zwei Buchstaben - Trigramme wären Kombinationen aus drei Buchstaben. "ie" ist dort gelb und damit recht häufig. Das wäre ein Versuch wert, überprüft zu werden. Das wäre dann "Qe" für "ie" nach jetzigem Stand, wenn "Qn" "in" wäre. "Qe" kommt 5x im Text vor und "Qn" 7x. Und auch das Bigramm "in" ist gelb und häufig. Versuchen wir es und machen das "Q" zu einem "i":ABCeEFGCnIEJ! KC JLIM KLI NLeMIeB AeBOeIM. KC PinKeIM Kie KOIe in KeN GCNReB eineI CSAePLBBenen TLCSeI Tei Ken FOONKinLMen nONK RGeiCnKPCenPRiA ANLK nCBB UCnFM IieTen nCBB nCBB SinCMen CnK OIM LEJM ANLK neCnCnKRGLnRiA UCnFM VieN IieTen einI SinCMen. VieB IULII!
Ja, ich glaube, wir sind auf einem guten Weg. Ich kann "eineI" lesen, könnte für "einen", "eines" oder "einem" stehen. "Kie" könnte gut für "die" stehen, "Ken" für "den". Wir ersetzen jetzt einfach mal K->d und schauen uns den Text noch einmal an.
ABCeEFGCnIEJ! dC JLIM dLI NLeMIeB AeBOeIM. dC PindeIM die dOIe in deN GCNReB eineI CSAePLBBenen TLCSeI Tei den FOONdinLMen nONd RGeiCndPCenPRiA ANLd nCBB UCnFM IieTen nCBB nCBB SinCMen Cnd OIM LEJM ANLd neCnCndRGLnRiA UCnFM VieN IieTen einI SinCMen. VieB IULII!
Nach Geocaching-Begriffen suchen
Jetzt haben wir schon einige Buchstaben ersetzt. Versuchen wir jetzt, ein paar Wörter zu erraten. Und wieder an den Kontext denken. Was glauben wir im Klartext vorzufinden? Was steht denn gewöhnlicherweise dort immer wieder drin? Hier eine kleine Liste aus meiner Erfahrung:- Teil der Koordinaten: Koordinaten, Koords, Nord, Ost, North, East, Grad, Minuten, Sekunden, Punkt, Komma, ...
- Zahlwörter: null, eins, zwei, drei, vier, fünf, sechs, sieben, acht, neun, zehn, elf, zwölf, ...
- Das Objekt der Begierde: Final, Cache, Dose, Behälter, Box, ...
- Der Versteckort: Wald, Lichtung, Baum, Wurzel, Wurzelstock, Hasengrill, ...
- Beglückwünschungen: Glückwunsch, Gratulation, Toll gemacht, Bravo, ...
- Motivationen: Viel Glück, in die Wanderschuhe, raus in die Natur und dergleichen
- Sonstiges: keine Spoiler, suchen, finden, loggen, Stift mitnehmen, Angel nicht vergessen, ...
AlCeEFGCnsEJ! dC JasM das NaeMsel AelOesM. dC PindesM die dOse in deN GCNRel eines CSAePallenen TaCSes Tei den FOONdinaMen nONd RGeiCndPCenPRiA ANad nCll pCnFM sieTen nCll nCll SinCMen Cnd OsM aEJM ANad neCnCndRGanRiA pCnFM vieN sieTen eins SinCMen. viel spass!
Und wenn das vor "viel spass" nicht mal "vier sieben eins" heißen soll (N->r, T->b). Und "nCll" ist bestimmt "null" (C->u).
AlueEFGunsEJ! du JasM das raeMsel AelOesM. du PindesM die dOse in der GurRel eines uSAePallenen bauSes bei den FOOrdinaMen nOrd RGeiundPuenPRiA Arad null punFM sieben null null SinuMen und OsM aEJM Arad neunundRGanRiA punFM vier sieben eins SinuMen. viel spass!
Weitere Wörter kombinieren / vervollständigen
"nOrd" steht da ja schon richtig (O->o), dann wird "OsM" "ost" heißen (M->t), dann folgt eine Zahl und "Arad" ist wohl "grad" (A->g). Laut Listungkoordinaten sich wir bei 8 Grad Ost, dann wird "aEJM" "acht" sein (E->c, J->h, nochmal M->t).gluecFGunsch! du hast das raetsel geloest. du Pindest die dose in der GurRel eines uSgePallenen bauSes bei den Foordinaten nord RGeiundPuenPRig grad null punFt sieben null null Sinuten und ost acht grad neunundRGanRig punFt vier sieben eins Sinuten. viel spass!
Der Rest ist dann wirklich nicht mehr schwer zu erraten. Der Klartext heißt demnach
glueckwunsch! du hast das raetsel geloest. du findest die dose in der wurzel eines umgefallenen baumes bei den koordinaten nord zweiundfuenfzig grad null punkt sieben null null minuten und ost acht grad neunundzwanzig punkt vier sieben eins minuten. viel spass!
Das Kombinieren und das Suchen und Ersetzen kann richtig Spaß machen, gerade auch im Team. Einer schreibt und die anderen versuchen verschiedene Ansätze und melden Ersetzungen, die vielversprechend sind.Am Anfang muss man sich ein wenig mit den Eigenschaften und Besonderheiten der deutschen Sprache befassen und sich mit den Häufigkeitsverteilungen beschäftigen. Die Seite ist eine wahre Schatzkiste an nützlichen Informationen, die man auf einen Text anwenden kann. Denn man kann auch andere Strategien benutzen und zum Beispiel nach Doppelbuchstaben Ausschau halten. Und die Seite verzeichnet auf Infos für andere Sprachen, wie etwa englisch, spanisch oder französich, falls man mal einen Cache im Ausland sucht. Dann ist es aber sehr von Vorteil, wenn man die entsprechende Sprache auch spricht, um Wörter erraten zu können.